This article was last updated on <span id="expire-date"></span> days ago, the information described in the article may be outdated.
现代互联网的很多流量都是承载在 HTTP 协议之上的,伟大的工程师前辈们制作了许多非常优秀的框架/协议,在我们的开发过程中帮助我们减轻了很多的工作,所以在业余时间,我想我们应该更加了解这些框架/协议的工作原理。
因此我构建了这个系列文章,以及 Flaks 项目(没错就是 Flaks – 高射炮),它模仿了一些 Flask 框架的特性(路由、可配置、…)并添加了一个简单的 并行/异步 HTTP 服务器与 CGI 支持;在这个系列文章中会较为详细的讲解该框架的构建流程以及思路,希望大家喜欢。
这是这个系列的第三篇文章,本篇文章我们实现服务器的 CGI 与 WSGI 支持。
本人才疏学浅,如果在文章中有任何错误,还请大家不吝指正。
这个系列文章将会由以下几篇文章组成:
- 从
socket到selectors选择器 -
HTTP请求解析 -
WSGI与CGI支持 - 生成
HTTP响应 - 视图函数与路由
- 尝试
asyncio的协程异步 I/O
上篇文章我们对从 socket 服务器发送过来的请求数据进行了处理,并将其封装成了 Request 类;在这里,首先关注一下类内部都封装了哪些信息:
1 | class Request: |
在类的构造函数 docstring 中,我描述了封装的全部信息以及其意义。其实 WSGI&CGI 要做的也就是将这些信息传递给程序的其余组件/其他进程。
CGI 支持与并行化处理
CGI - Common Gateway Interface.
它并不是一种什么的特殊编程语言,只是编程语言之间用来通讯的一组协议。后端程序经常会涉及到多个组件,而这些组件很有可能是由不同的编程语言构成。我们一般在不同的编程语言之间进行通讯的方法有以下几种:
- 构建专门的
Web接口,使用HTTP协议发送JSON数据 - 直接使用原生的
socket接口进行通讯 - 使用共享内存(仅限本机)
- 使用管道(仅限本机)
- ….
CGI 和上面的这些方法一样,用于在不同的程序之间传递信息,只不过它传递信息的载体比较特殊一些 —— 环境变量。
环境变量
文章的开头我们详细的列出了在 Request 类中所封装的信息,而 CGI 标准需要传递的信息有如下这些:
| 名称 | 意义 | 对应 Request 类中的封装变量 |
|---|---|---|
CONTENT_TYPE |
所传递来的信息的MIME类型 | self.headers["Content-Type"] |
CONTENT_LENGTH |
标准输入STDIN中可以读到的有效数据的字节数 | self.hedaers["Content-Length"] |
HTTP_COOKIE |
客户机内的 COOKIE 内容 | self.cookie |
HTTP_USER_AGENT |
包含版本数或其他专有数据的客户浏览器信息 | self.headers["User-Agent"] |
PATH_INFO |
紧接在CGI程序名之后的其他路径信息 | self.path |
QUERY_STRING |
如果服务器与CGI程序信息的传递方式是GET,变量的值即使所传递的信息 | self.query |
REQUEST_METHOD |
提供脚本被调用的方法 | self.method |
SCRIPT_FILENAME |
CGI脚本的完整路径 | self.path |
SCRIPT_NAME |
CGI脚本的的名称 | self.path.split('/')[-1] |
SERVER_NAME |
WEB 服务器的主机名、别名或IP地址 | self.headers["Host"] |
SERVER_SOFTWARE |
调用CGI程序的HTTP服务器的名称和版本号 | settings.SERVER_NAME |
在以上信息全部都提取到出来之后,只需要将他们全部放在 os.environ 即可(所有的信息全部转化为字符串)。这样我们就完成了 CGI 协议的支持。
但是有朋友可能会问,那到底怎么运行程序呢?下面,我们使用 subprocess 并行化的处理 CGI 脚本的执行。
并行化处理
首先,CGI 脚本可能以任何语言写成,一般在解释型语言的脚本首行,会看到以 #! 开头的一行代码;这个东西叫做 shebang ,它的本意就是指示 exec 函数以什么程序去执行这段代码。在 CGI 标准中这个东西同样适用。
所以我们需要读取首行的 shebang 获取执行的程序:
1 | with open(scriptfile, "r") as handler: |
获取到 excuter 变量之后,通过 subprocess.Popen 去执行它即可:
1 | process = subprocess.Popen((executer, scriptfile), |
可以看到,通过 Popen 函数的 env 变量将上面的环境变量传递给了新的进程,而 stdout 使用管道将 CGI 脚本的输出返回给我们程序(简单地说就是那边打印什么,这边得到什么)
之后,我们设置 CGI 脚本最大的执行时间为 settings.CGI_TEMOUT,这样可以防止脚本中的死循环/无意义长时间I/O等待。当超时时,首先杀掉执行的进程,之后向客户端发送 408 响应;
而如果脚本的执行发生了错误,process.returncode 则会不为 0。这时向客户端发送 502 响应;
如果一切正常,构建一个 HTTP 200 的响应并将脚本执行的输出返回给客户端即可。
这样我们就构建了一个并行化执行的 CGI 服务器,而关于响应类的封装,我们下一篇文章再讲。
WSGI 支持
WSGI 和上文所述的 CGI 本质上都是一样的,也是通过系统的环境变量传递 Request 类所封装的信息(并且需要的信息大多也都相同);唯一的区别点在于 WSGI 仅针对 Python 程序进行通讯,所以可能会多出几个字段(wsgi.multithread, wsgi.multiprecess, …)来描述关于并行的相关信息。
所以和上面的流程一样,只需要将符合 WSGI 规范的信息全部导出到环境变量即可,为了节省篇幅我不再重复。
而 WSGI 其实是定义在 PEP 3333 中的:PEP 3333 – Python Web Server Gateway Interface. 我在 request.py 中的 _set_environ 函数中也有较为详细的描述,有兴趣的同学可以看 这里。
小结
在程序的扩展性方面来说,WSGI 与 CGI 不过是程序之间通讯的一种协议,通过对它们的支持,我们的程序可以轻松的与很多现有的框架/程序进行对接,大大的增强了我们程序的扩展性。
而在 Web 服务器的架构方面,它们更重要的意义在于:实现了 HTTP 服务器与 Web 服务器的完全解耦。我制作了一张简单的图片来说明到我们框架的大概构架:
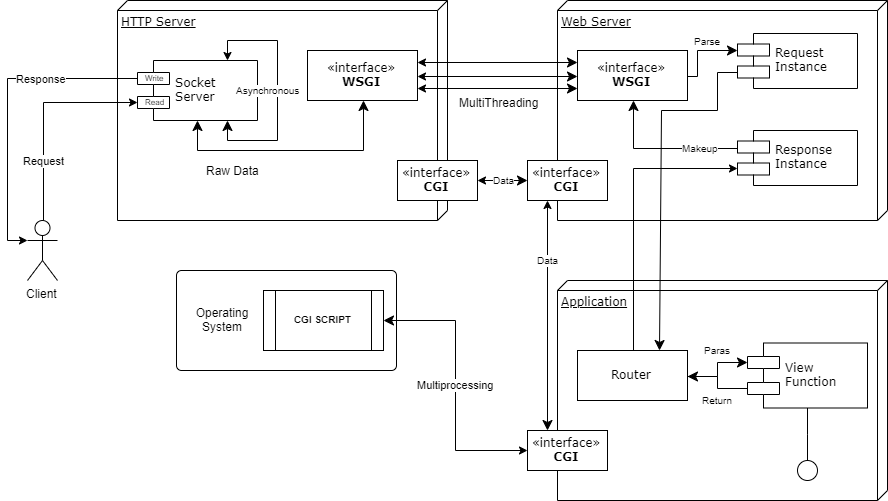
我们大部分的工作业已完成,下一篇文章将对 HTTP 的响应进行封装。
Comments