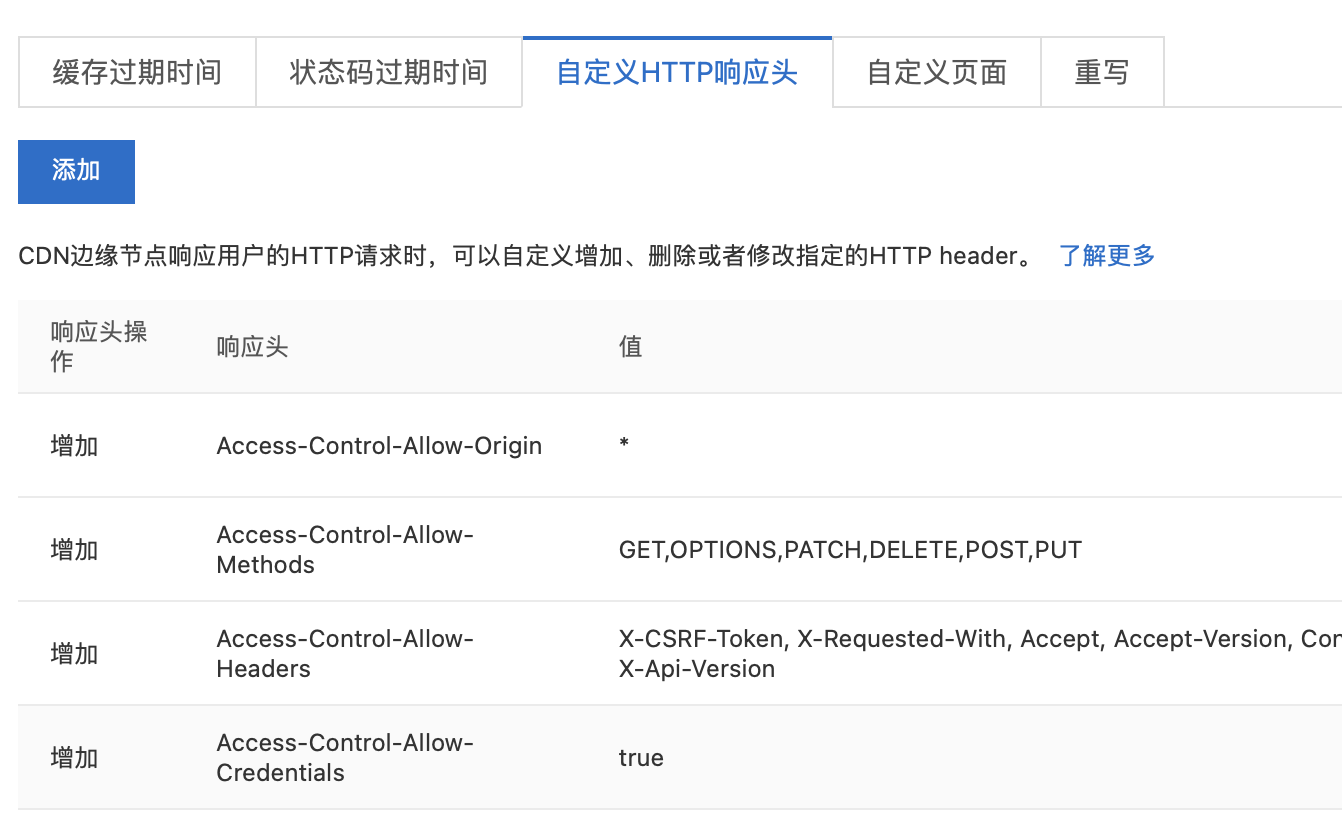
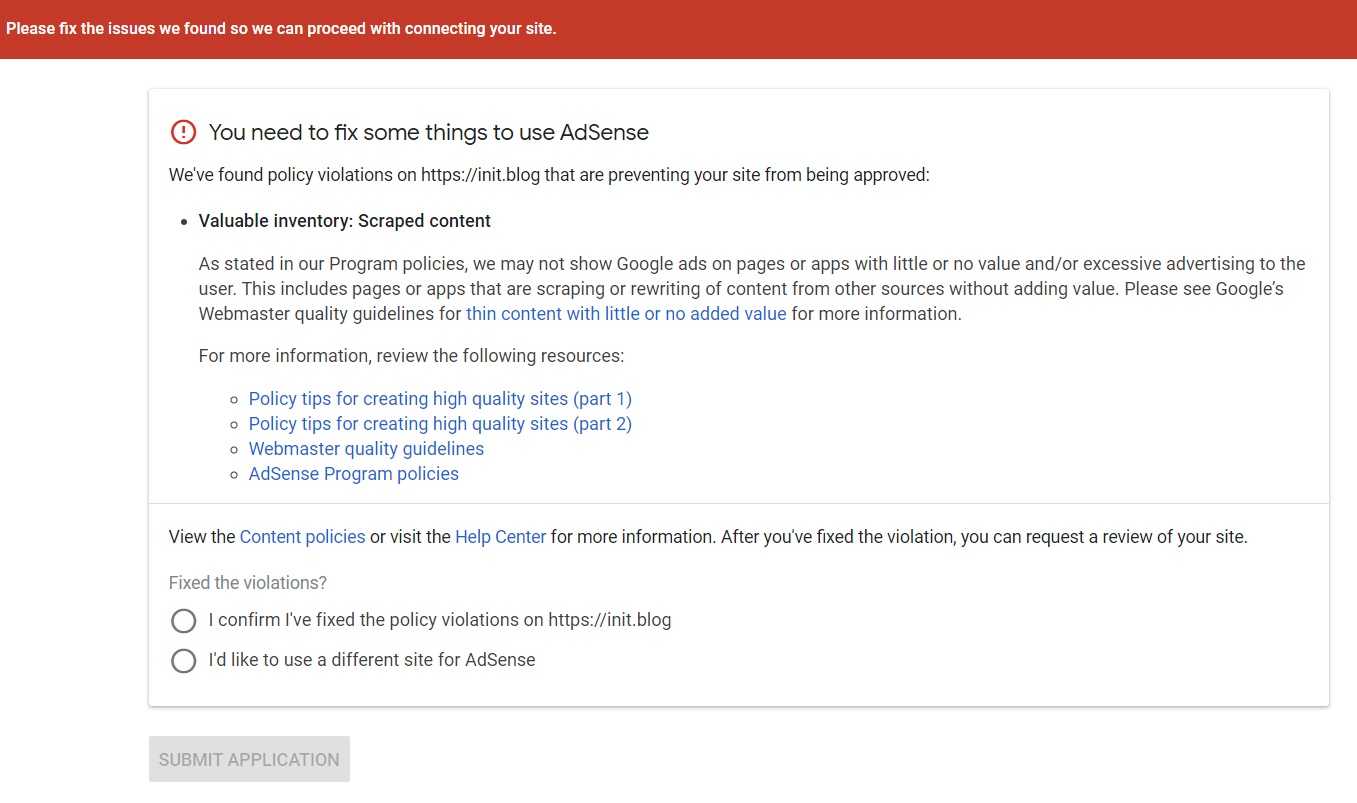
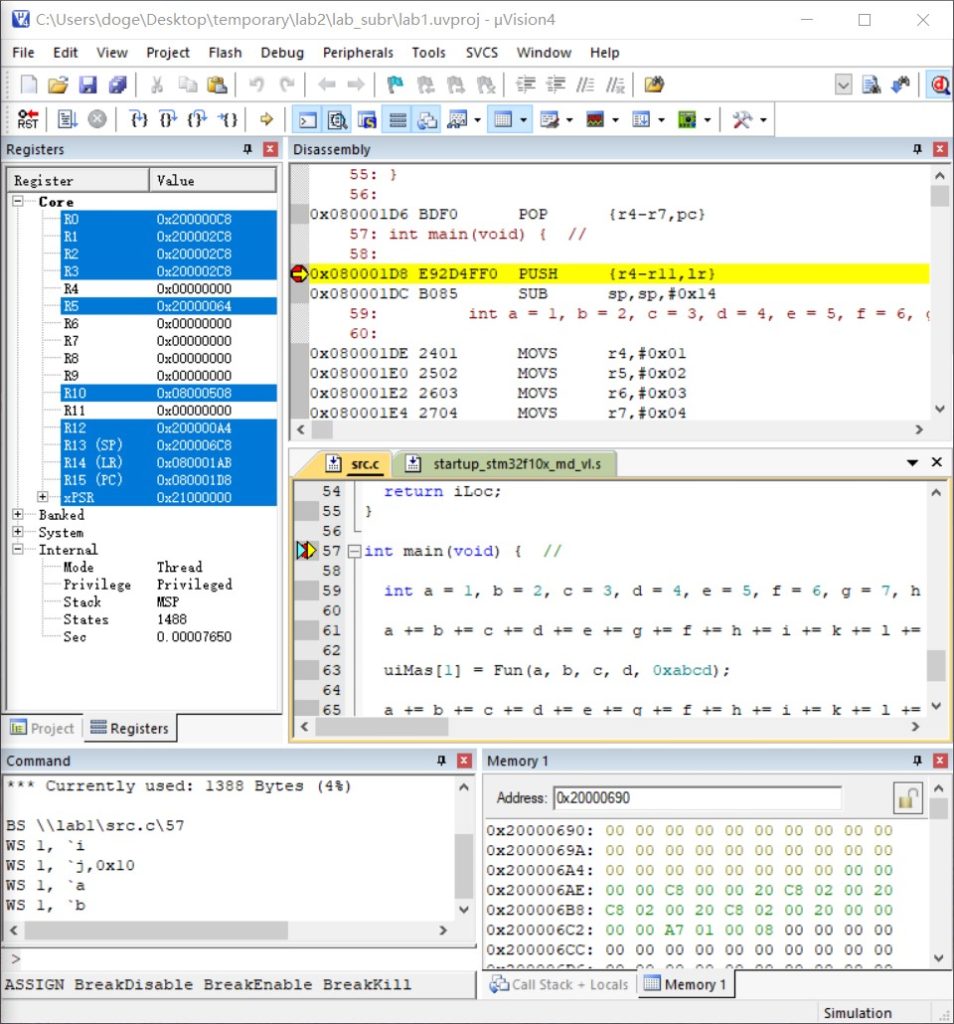
之前在 Vultr 充值了 25 刀,加上给的 25 刀 Credit,简单搭了一个 VPN,用起来还算可以;只是每月最低 5 刀的价格(2.5 刀仅在美国地区有,欧洲的访问速度太差)让这 50 刀很快就花完了。出于节省成本的原因,我找了另一家俄罗斯本土的服务提供商,他们在赫尔辛基提供的机器很符合要求:
- 离圣彼得堡足够近,直连延迟仅 10ms 左右
- 内存仅 500 MB、HDD 5 GB存储
- 100 Mbps 带宽不限流量
- 最重要的,每月 152 卢布,按照现在的汇率仅 1.5 美元/月左右
但是他们这种垃圾机器仅提供 IPv6 单栈网络,要在上面部署代理服务需要花点时间。
0. 使用 Warp 给机器添加 IPv4 访问能力
因为 GitHub 等站点仅有 v4 地址,所以如果想要部署 GitHub 上的软件就需要给机器添加一个 IPv4 网络栈,这一点用 Warp 可以方便实现。同时可以使用 Zero Trust 版本的 Warp 来组建内网。
首先在服务器上安装 warp-cli:
1 | # Add cloudflare gpg key |
默认 Warp 的工作模式是类似 TUN 的模式,但实际上只需要让它提供一个 Socks 的代理接口。为了在 Zero Trust 中使用这个功能,可以在 Cloudflare Zero Trust 管理面板中新建一个设备 Profile(Settings - Device Settings - Create Profile),规则按照自己的条件来选,我这里选择了用户 + Linux 操作系统。之后在 Service mode 中选择 Proxy mode(默认是 Gateway with WARP):
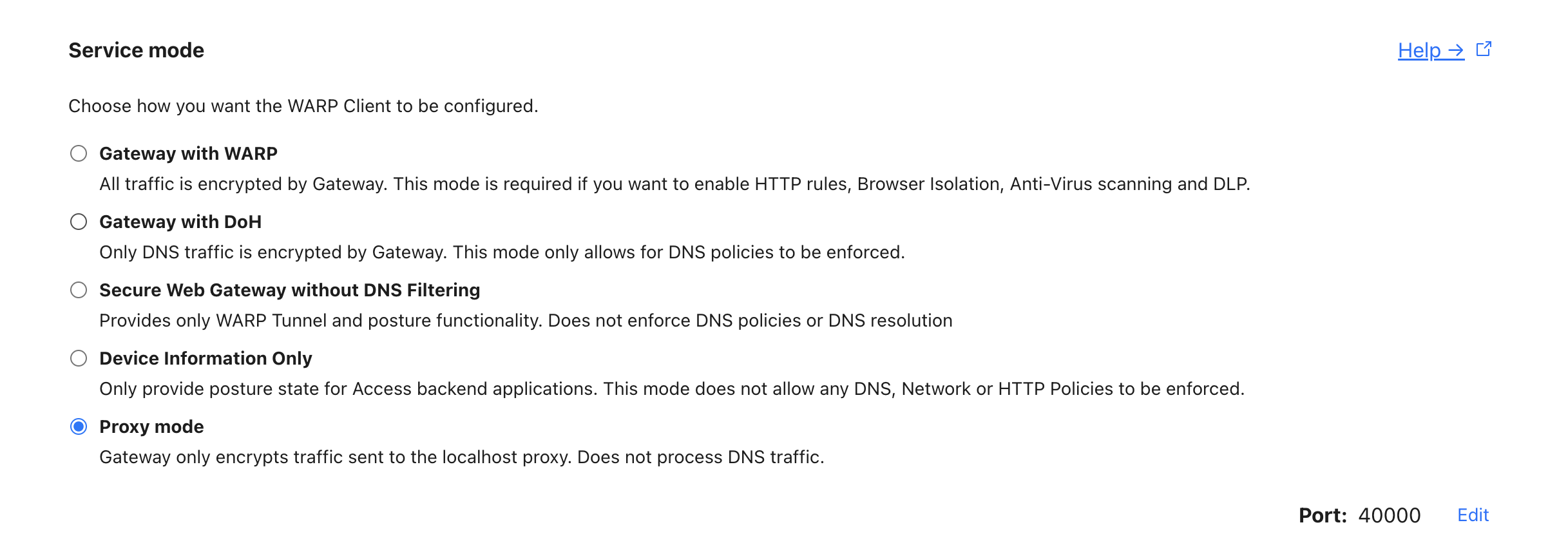
代理端口使用默认的 40000 即可。
之后在服务器上部署 Zero Trust Warp:
在随便一个浏览器里面打开
https://[teams-id].cloudflareaccess.com/warp这个链接,会要求你登陆自己的组织,登陆成功后会打开这样一个页面: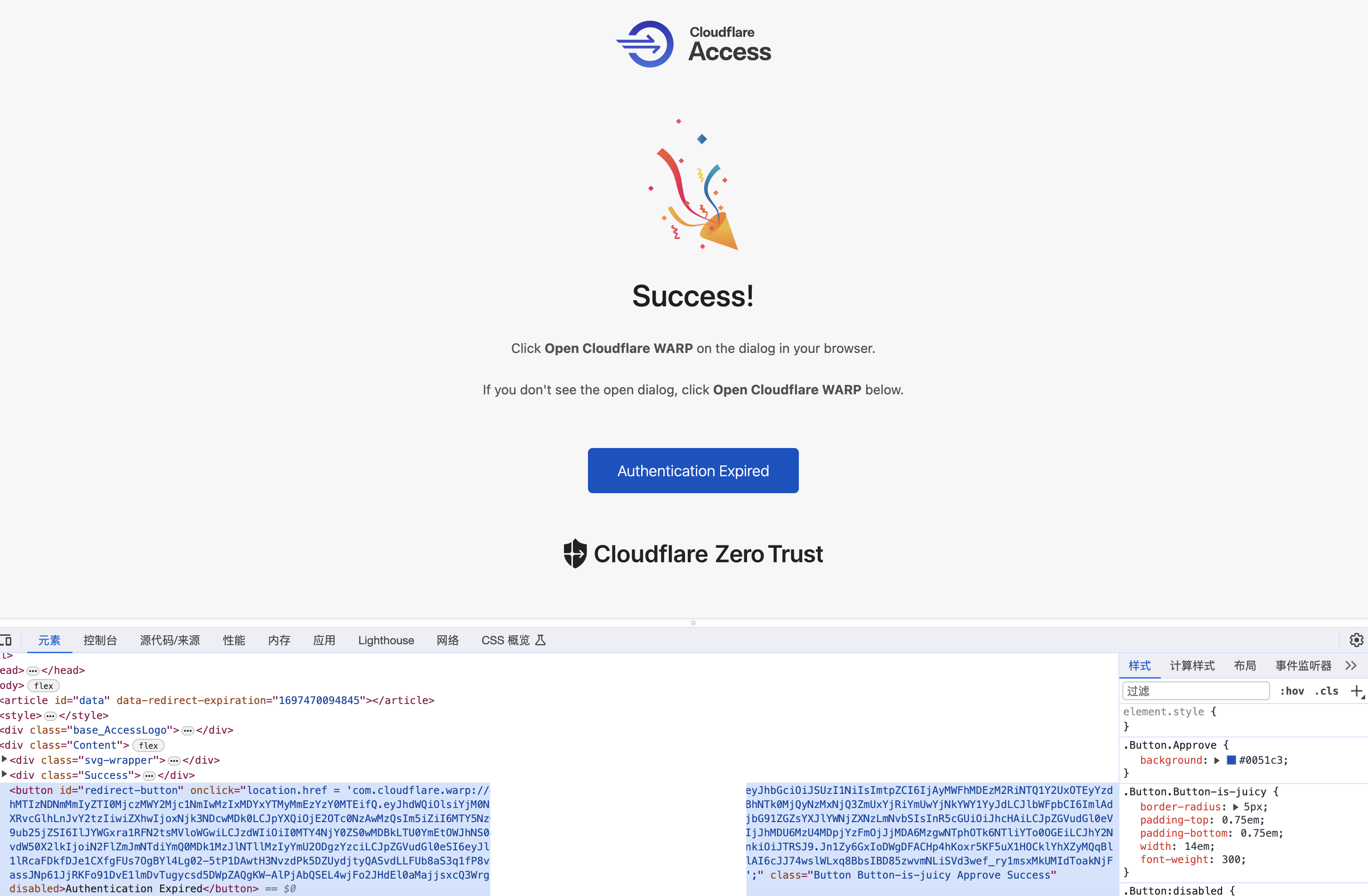
把 Authentication 按钮
href单引号内的内容复制出来com.cloudflare.warp://...,之后在服务器上执行:1
warp-cli teams-enroll-token [href]
如果如果没什么问题,服务器上的 Warp 就部署好了。
连接上服务:
1
warp-cli connect
并在
~/.bashrc中增加代理:1
export ALL_PROXY="socks5://127.0.0.1:40000"
验证一下:
1
curl api.ipify.org
如果没什么问题,应该可以看到服务器已经有了一个 IPv4 的地址。
1. 部署 Zero Trust Tunnel 并提供 SSH 访问
俄罗斯的落后是全方位的,2023 年了,我的 ISP 还没有提供 IPv6。上面的操作都是在 noVNC 里面进行的,由于没有复制粘贴,十分不便。好在 Cloudflare Zero Trust 提供了一个 Tunnel 的功能,相当于一个内网穿透隧道,于是边可以将 SSH 服务映射出来:
首先创建一个 Tunnel(Access - Tunnels - Create a Tunnel),随便给一个域名或者子域,并在 Configure 里配置到 SSH 服务的映射:

记得这里的 Path 需要留空,这样公网上对给定域的访问就会被 Tunnel 转发到服务器的 22 端口上。
之后需要在服务器上安装
cloudflared,这是 Cloudflare Tunnel 的管理软件:1
2
3
4
5
6
7
8
9# Add cloudflare gpg key
sudo mkdir -p --mode=0755 /usr/share/keyrings
curl -fsSL https://pkg.cloudflare.com/cloudflare-main.gpg | sudo tee /usr/share/keyrings/cloudflare-main.gpg >/dev/null
# Add this repo to your apt repositories
echo 'deb [signed-by=/usr/share/keyrings/cloudflare-main.gpg] https://pkg.cloudflare.com/cloudflared jammy main' | sudo tee /etc/apt/sources.list.d/cloudflared.list
# install cloudflared
sudo apt-get update && sudo apt-get install cloudflared在 Tunnel 的管理页面会有一个 Token,使用下面这个命令连接到你刚刚创建的 Tunnel:
1
sudo cloudflared service install [your-tunnel-token]
很重要的,由于垃圾机器是 IPv6 单栈的,Tunnel 的默认链接使用 IPv4,所以使用
sudo systemctl status cloudflared会发现链接创建失败:1
Failed to create new quic connection error="failed to dial to edge with quic: INTERNAL_ERROR: write udp [::]:35102->198.41.200.113:7844: sendto: network is unreachable" connIndex=0 ip=198.41.200.113
需要在
/etc/systemd/system/cloudflared.service配置文件中增加默认使用 IPv6 的选项:1
ExecStart=/usr/bin/cloudflared --edge-ip-version 6 --no-autoupdate --config /etc/cloudflared/config.yml tunnel run
然后重新启动
cloudflared服务:1
2sudo systemctl daemon-reload
sudo systemctl restart cloudflared最后一步,在需要登陆的客户端机器上也安装
cloudflared,并编辑~/.ssh/config文件,对指定的 Host 使用 Cloudflared 软件连接 SSH:1
2
3Host [tunnel domain]
IdentityFile /users/doge/.ssh/[private-key-file]
ProxyCommand /usr/local/bin/cloudflared access ssh --hostname [tunnel domain]最后使用 SSH 验证一下:
1
ssh [tunnel domain]
如果没有什么问题,就可以登陆到服务器上了。这样我们使用 Cloudflare Tunnel 从 443 端口转发了 SSH 流量到机器了,可以看到,每次登陆的地址都是 ::1,这是因为使用了隧道的缘故:
1 | Last login: Mon Oct 16 18:38:28 2023 from ::1 |
2. 部署 xray-core 并在 Tunnel 上使用 websocket 协议
部署 xray-core:
1 | wget https://github.com/XTLS/Xray-install/raw/main/install-release.sh && sudo bash install-release.sh |
因为需要使用 Tunnel 将流量转发到机器上代理,能够穿透 Cloudflare 这样 CDN 的传输方式一般采用 websocket,并且由于 Cloudflare 代理了流量,甚至都不需要配置 SSL 证书;并且,因为使用 Tunnel 的缘故,这些端口只需要侦听本地地址即可。
下面给出一份可用的模板,这里在 80 端口上使用 VLess 协议,并在 /ws 路径上回落到本地的 8081 端口处理 websocket 流量:
1 | { |
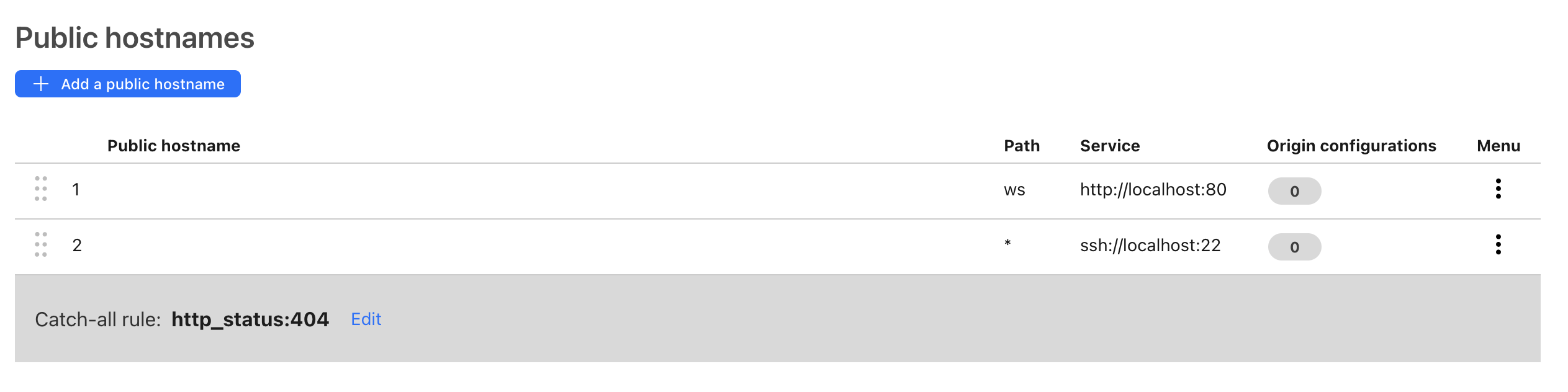
之后在 Tunnel 的配置面板里面增加一个 Public hostname 用来转发代理流量。
很巧妙的是,由于使用了 websocket,所有的代理流量只会匹配到 /ws 这个路径下,而刚刚设置无路径的 SSH 服务流量只会匹配到 / 根目录下,所以其实可以使用同一个子域:
3. 使用 Warp 代理出口流量解锁 ChatGPT 及流媒体
因为 ChatGPT 还有很多流媒体都 ban 掉了很多 VPS 的 IP 段,所以想要访问这些服务,还需要把这些流量转发到 Warp 上。操作比较简单,只需要把上面 xray 配置文件中的 outbounds 改为 Warp 即可:
1 | { |
这里还可以使用 xray 的 routing 功能配置路由实现更多媒体解锁以及广告屏蔽之类的功能。
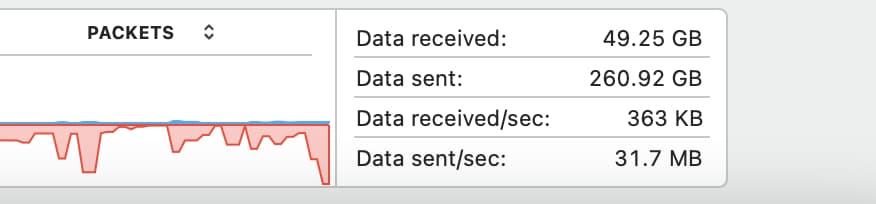
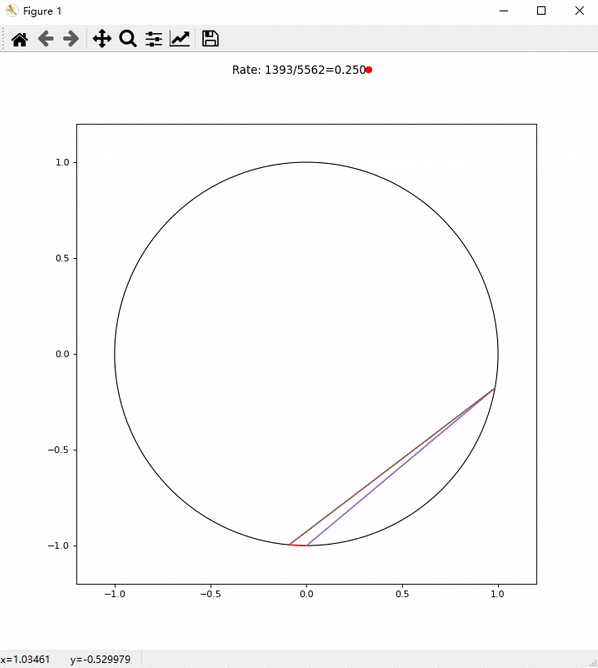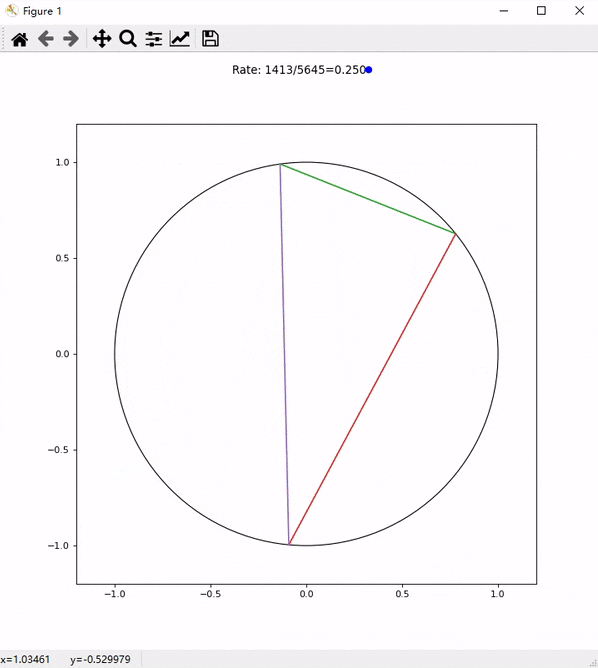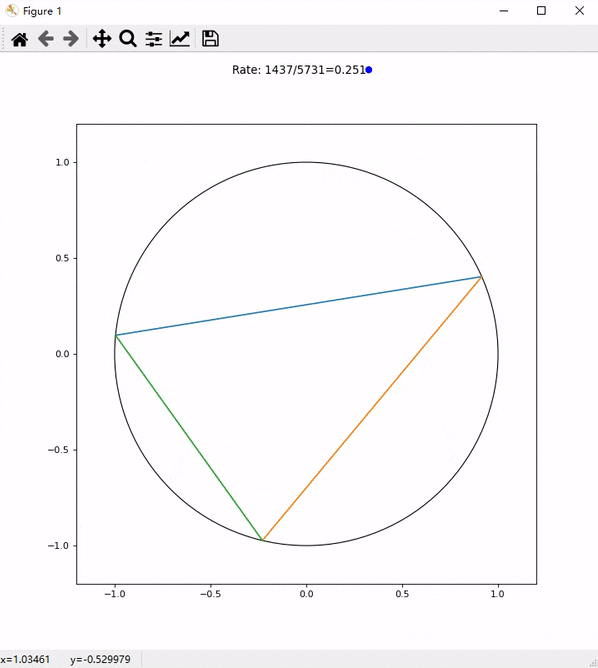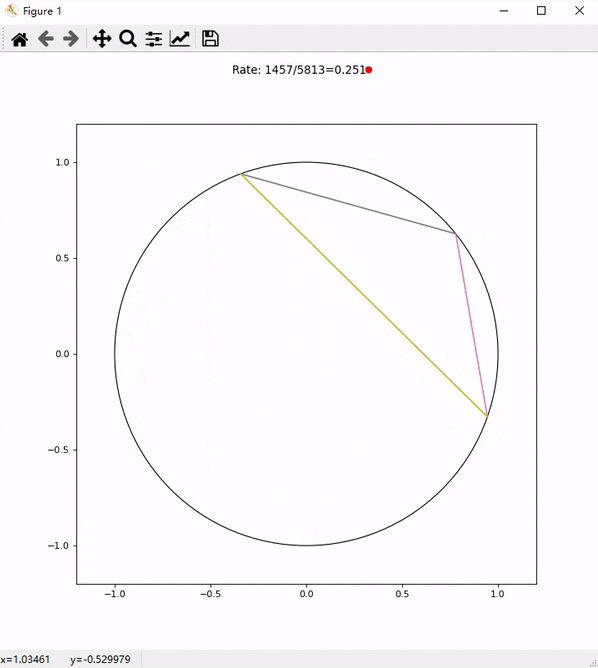
4. 速度测试
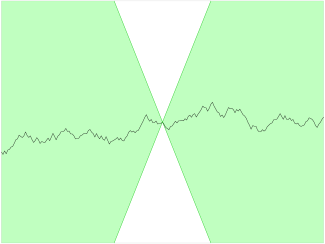
通过 Cloudflare Tunnel 代理的代理基本可以跑满家里的 100Mbps 带宽了:
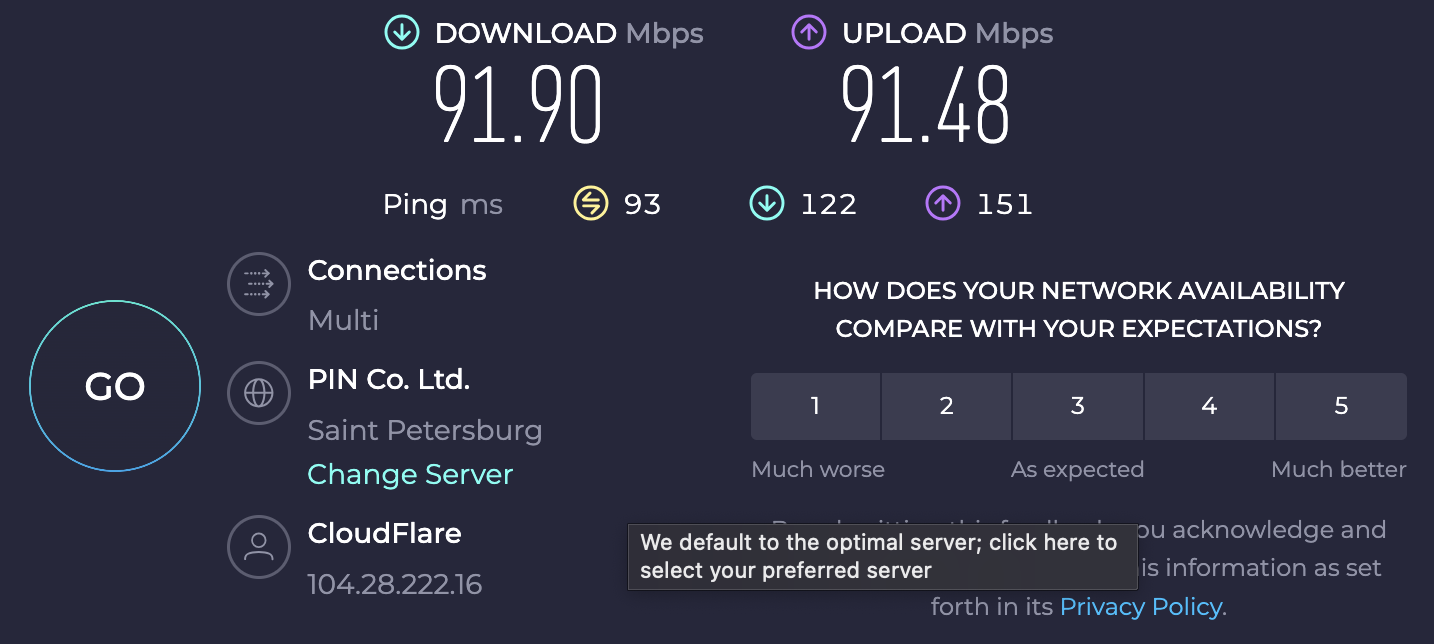
相比之前直连瑞典 Stockholm 代理的速度,甚至还要更快一些:
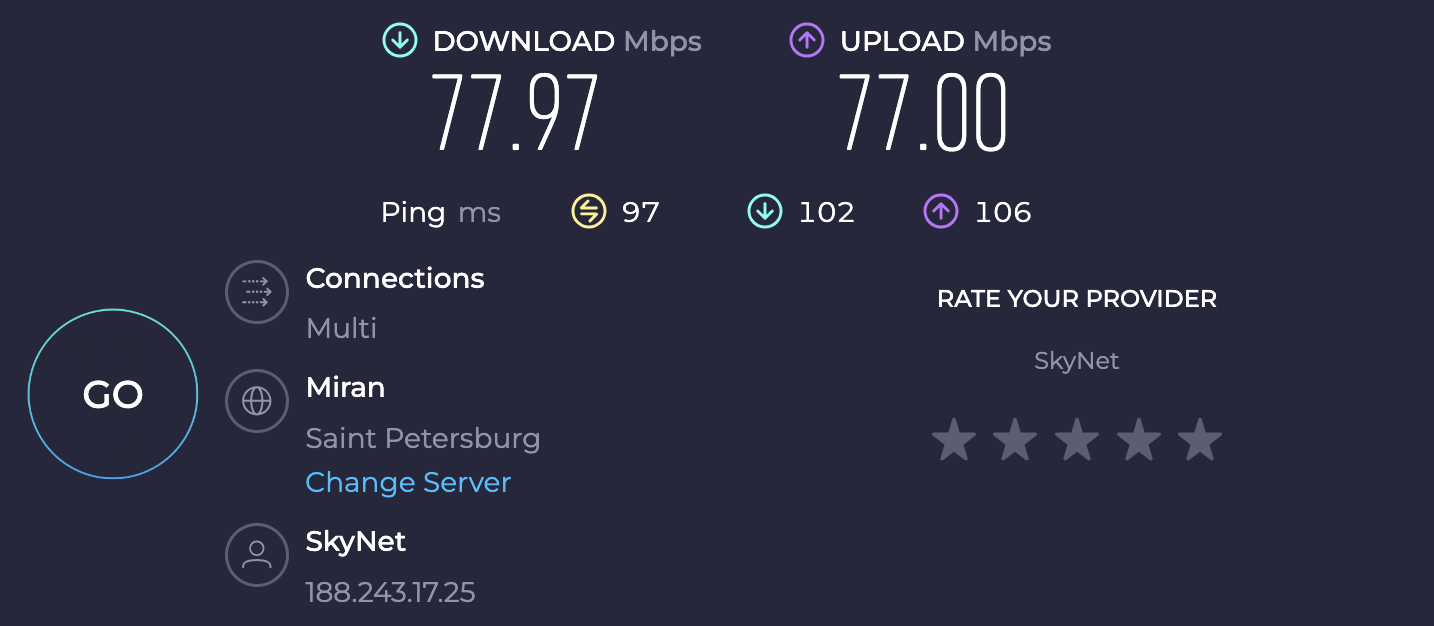
并且 ChatGPT、Bard 等服务也都可以正常解锁;100ms 之内的延迟,使用起来也比较丝滑。猜测这是因为 Zero Trust Tunnel 是基于 Argo 的,它可以提供更加优质的回源路径:
- 以往访问在 Cloudflare CDN 上部署的 a.com 时,请求一般会被最近的节点接受,例如圣彼得堡最近的节点就是 LED,之后会在公网上
proxy_pass到源服务器上。 - 而经过 Argo 的 a.com 的请求会首先由 LED 节点接受,之后 Cloudflare 会将这个请求转发至 HEL - 也就是赫尔辛基节点,在这个过程中走的是 Cloudflare 的内部网络,相对来说更快一些。
5. 总结与其他
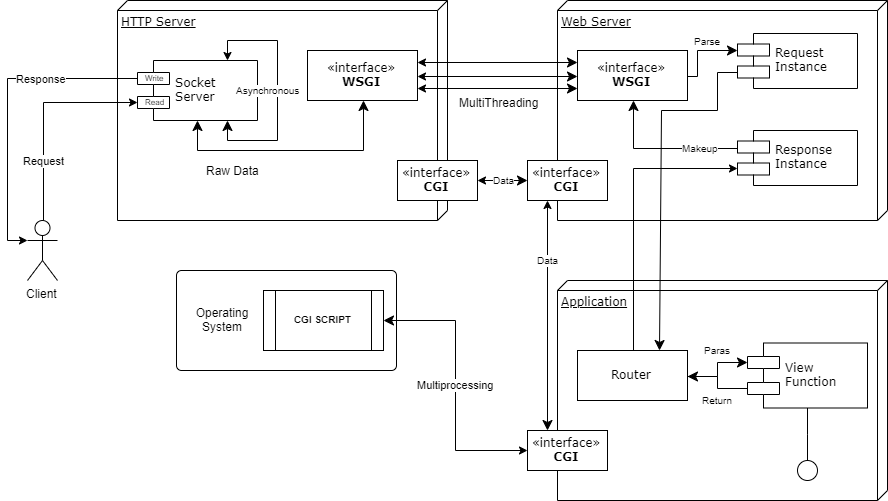
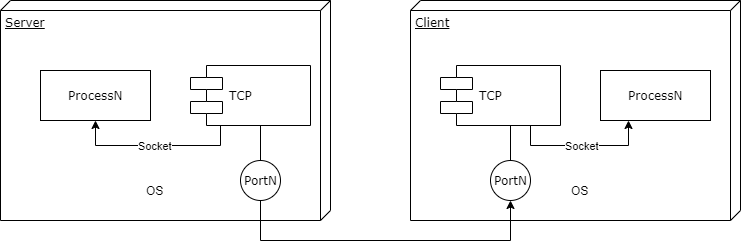
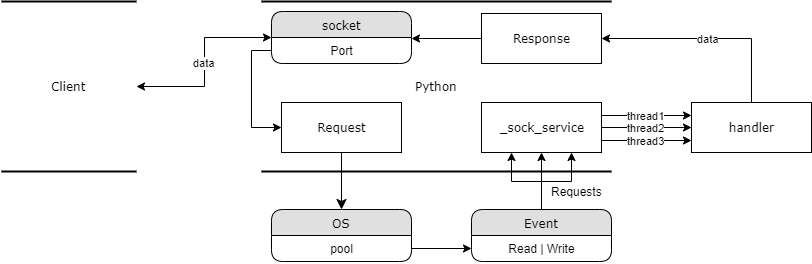
经过上面的步骤,我们实现了一个很有意思的网络结构(这张图是从 Cloudflare 官网偷的),其中我们的 Server 到 Internet 的流量也是经过 WARP 的:

这也就意味着在用户看来,服务器被 Cloudflare 的网络保护了;而对于经由代理访问的网站看来,请求又是从 Cloudflare 发来的 —— 整个过程中我们的服务器被完全包裹起来了,所有外人能知道的唯一信息就是服务器所处的大致地理位置。
而如果打开 Zero Trust - Settings - Network 里面的 WARP to WARP 以及 UDP、ICMP 转发的话,还可以在客户端上登陆到 Zero Trust Teams,并配置 Private Network,就可以实现一个内网了。
在 Applications 里面还可以添加一些 Self-hosted 应用,比如 Web-based SSH 服务,网上有很多教程,在此便不赘述,我个人就在这里部署了一个配置转换服务,这样新的用户就可以通过申请一个域邮箱登陆,之后一键下载配置代理。另外,还可以在 Gateway 里面添加自己的 DNS 服务器,实现内网解析。
不得不说,Zero Trust 真的是 Cloudflare 提供的一个非常好用的功能,并且最关键的,这个服务是免费的。想起上篇关于 DNSSEC 的介绍文章中就曾提及 Cloudflare 所提供的很多优质服务(例如 1.1.1.1 DNS),以及为推动互联网进步所做的很多努力。希望中国的互联网公司也可以少些内卷,多创造出一些这样令人兴奋的,造福大家的基础服务。
]]>