This article was last updated on <span id="expire-date"></span> days ago, the information described in the article may be outdated.
现代互联网的很多流量都是承载在 HTTP 协议之上的,伟大的工程师前辈们制作了许多非常优秀的框架/协议,在我们的开发过程中帮助我们减轻了很多的工作,所以在业余时间,我想我们应该更加了解这些框架/协议的工作原理。
因此我构建了这个系列文章,以及 Flaks 项目(没错就是 Flaks – 高射炮),它模仿了一些 Flask 框架的特性(路由、可配置、…)并添加了一个简单的 并行/异步 HTTP 服务器与 CGI 支持;在这个系列文章中会较为详细的讲解该框架的构建流程以及思路,希望大家喜欢。
这是这个系列的第一篇文章,本篇文章我们使用 Socket 模块搭建一个简易的 Web 服务器。
本人才疏学浅,如果在文章中有任何错误,还请大家不吝指正。
这个系列文章将会由以下几篇文章组成:
- 从
socket到selectors选择器 HTTP请求解析WSGI与CGI支持- 生成
HTTP响应 - 视图函数与路由
- 尝试
asyncio的协程异步 I/O
TCP 与 Socket
从根本上讲,HTTP 协议只是一套指定消息格式的语言,通过这一套语言允许我们在两台计算机之间发送有意义的信息(也就像我在之前的文章中说过的 —— 协议就是计算机之间的语言)。
我们都知道 HTTP 协议是工作在 TCP 协议之上的(当然现在有更新的QUIC,在此我们不讨论它)。根据 OSI 的分层模型,TCP 作为工作在更底层的协议对上层 HTTP 的数据报进行进一步封装,于是在 HTTP 开始工作之前,我们先要确保两台计算机之间已经建立了 TCP 连接。
而数据仅仅交给计算机硬件是没有意义的,我们需要进程来对数据进行处理。这样就相当于在服务器-客户端的两个进程之间建立了连接,我们将这样的一组唯一的连接信息:(进程PID+端口号+地址)抽象成为 socket,并对 TCP 进行了进一步封装,这样我们就可以在两台计算机的不同进程之间发送消息了。
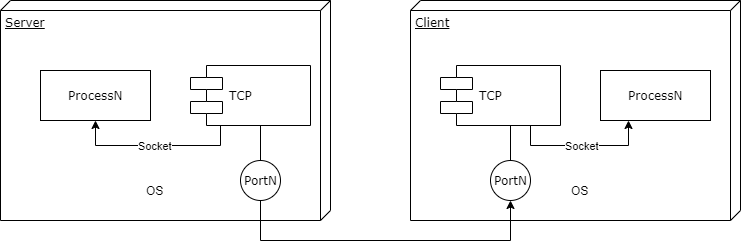
所以很多朋友不用把 socket 想的过于神秘和特殊,它和其他的 IPC (Inter-Processing Communication) 方法的本质是相同的(其他的有类似管道、FIFO管道、Shared Memory 等等),都是提供了在不同进程之间交换信息的方法。
而在 Python 中有开箱即用的 socket 库可供我们使用,我们一般仅仅需要使用这样的代码就可以侦听一个端口上的连接请求并在有请求时建立与客户端的连接:
1 | import socket |
需要注意的是,因为 TCP 是基于数据流的协议,我们需要指定获取的数据报最大长度(也就是 BUFFER),而超出这个大小的数据就会被忽视(当然我们也可以不断地获取直到一个包被完整的发完),这也就是很多包括 Nginx 之类的伺服器会要求指定一个包的最大长度的原因,超出则会直接返回 413 Too Large 之类的错误。
监听多个连接
上面的代码已经可以工作了,在浏览器中访问:127.0.0.1:65432,没有其他问题的话,你应该已经可以看到一个亲切的 Hello World 问候了。
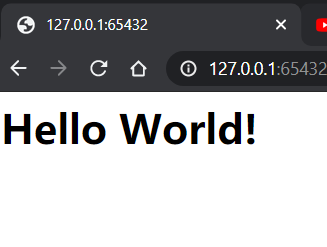
正如你所见,HTTP 协议的工作并不复杂。而关于响应的内容,我们暂且留到下一篇文章再说。除此之外你可能发现了,我们的代码仅仅只能运行一次,第二次需要重新启动,而且有一定几率出现打开失败。
这是因为我们在这里仅仅监听了一次连接请求,要解决这个问题,我们只需要在连接外面加上一层 while True 即可。
但是这样还不够,我们的一个端口仅仅只能处理一个连接,如果同时有多个浏览器请求我们的“服务器”,则他们的请求就会被全部丢弃,这并不是我们想要看到的。
在 socket.listen 方法中有一个可选项 —— maxsize ,通过该选项,我们可以指定同时等待处理的连接个数,这样我们对上面的代码进行修改后就可以处理多个连接了:
1 | import socket |
使用 Selectors 选择器
我们不满足于此,因为这样毕竟还是一个一个请求被处理的,我们想要更高效的处理请求,基于以下思路:
- 服务器接收到请求
- 在等待与客户端建立连接的时候侦听下一个请求
- 等待上一个请求处理完毕时调用一个给定的回调函数
- 下一个请求处理完毕
- …….
而在操作系统内部其实已经有相关的组件帮我们实现了这样的功能(类似协程),这个实现在 Windows 平台是我们熟悉的 select,在 Linux 平台的默认实现是 epoll. 而我们在应用过程中,可以使用 selectors 库,帮助我们实现对应的操作。下面我截取一段 server.py 中的代码进行说明:
1 | def start(self) -> NoReturn: |
其中,listener 是我们的侦听连接、_poll 是我们的事件连接池、_sock_accept 是当有可读事件发生时的回调函数。
我们可以看到,对于 selector 类型的实例,我们可以使用 register 将其绑定在事件管理器上,让它来提我们检测连接的相关事件。
而我们知道 socket 的本质也是一组文件描述符,所以 readble 的事件对它来说就代表在侦听端口上有新的消息到来(也许是新的连接请求,也许是以往的请求有新的数据发送…)
于是我们可以这样编写回调函数:
1 | def _sock_service(self, connection: socket.socket, mask: int) -> NoReturn: |
考虑到新的连接一旦被建立之后就不会再次建立了,我们将建立之后的连接的新可读事件绑定在 _sock_service 函数;而这个回调函数获取到信息之后将连接和客户端信息转发给 _handle 函数,它将会从连接缓冲区中读取消息,交予上层的应用层处理。而 _handle 函数的返回值则作为请求的响应值进行 sendall 操作返回给客户端,这样我们就完成了一个 HTTP 请求。
使用 threading 并行处理
我们已经可以高效的异步处理来自客户端的请求了,现在我们假设 _handle 函数进行了如下操作:
1 | def _handle(self, connection, client): |
同样是返回 Hello, World 问候,我们在其中加入了一个长达10s的休眠,用它来模拟一些非常长时间的I/O、计算操作。这时如果我们在浏览器中打开上述的地址时,会发现需要等待10s+的时间才可以,但是意外的,在这10s之内,我们试图打开新的访问请求也被延后了…
我们需要注意:selectors 内部的事件是由操作系统替我们调度的,而当事件被交予处理之后的延迟,由于我们的Python程序仅有一个线程,当这个主线程被阻塞之后,任何的事件都会被搁置处理,直到程序回复响应。
所以思路很简单,我们将对于每一个客户端请求使用一个独立的线程去执行即可:
1 | import threading |
我们给 _sock_service 方法使用上述定义的 thread 装饰器之后,每个请求就可以单独的使用一个线程去处理了,这样也就实现了并行(当然由于GIL的问题,这个并行也是切分时间片的),这里我画了一个简单的流程图供大家理解架构:
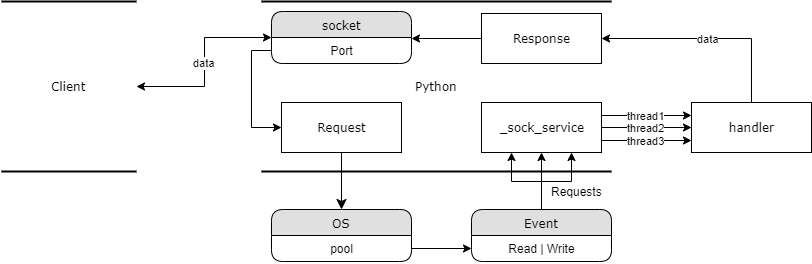
当然现在有了更先进的 asyncio 为我们提供了原生协程,包括 handle 函数中的 I/O 调度,后期我们会尝试用它来改写这一版的服务器。
现在我们已经可以很好的获取到来自客户端的请求,下一篇文章将要实现对 HTTP 请求的解析。
Comments